This post is additional content for my presentation at 2019’s BSides SF conference that describes the decision to not build Strelka with a microservices architecture.
Here’s my take on microservices: they’re for the 0.01% of application owners. Microservices, like any system architecture model, have advantages and disadvantages; for the majority of systems (including Strelka), I think the disadvantages outweigh the advantages. Don’t just take it from me, here’s a quote from Martin Fowler, an often-quoted proponent of microservices, taken from a blog entry named Microservice Premium:
… my primary guideline would be don’t even consider microservices unless you have a system that’s too complex to manage as a monolith.
Before deciding that Strelka should or shouldn’t use microservices, I did a lot of reading on the topic and this was the best advice that I found. Strelka’s system architecture is based on Lockheed Martin’s Laika BOSS which works at large-scale and without microservices – this suggested that Strelka didn’t need microservices, but I still went through the exercise of determining if their advantages would outweigh the disadvantages.
An Alternative to Microservices and Monoliths
One thing that Martin’s advice gets a little wrong is setting up a binary choice between microservices and monoliths. During my research I came across another option, one that sits somewhere between the other two: cookie cutter scaling. From what I can tell, this phrase was coined by Paul Hammant in his blog entry Cookie Cutter Scaling:
One particular style [of horizontal scaling], where all horizontally scaled nodes are identical (which I’ll call cookie cutter for the sake of this posting) pays dividends in terms of easy deployment and the ability to simply add boxes to add capacity to the stack.
What I found most interesting about this is that I had already been using cookie cutter scaling for years: this is the design used by Laika and Strelka. If you think you’re stuck choosing between microservices and monoliths, then I’d recommend looking at your codebase and determining if cookie cutter scaling might work for your application.
Microservices System Architecture
Despite knowing that Strelka doesn’t need microservices, I was curious to create a microservices design and see how different it would be compared to the cookie cutter architecture. As it turns out, it’s wildly different. Here is Strelka’s cookie cutter system architecture:
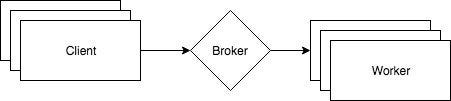
Wow, so simple! The architecture has two components: a broker and a worker, and you keep adding workers until you hit the scale you need.
Here’s a microservices architecture for Strelka:
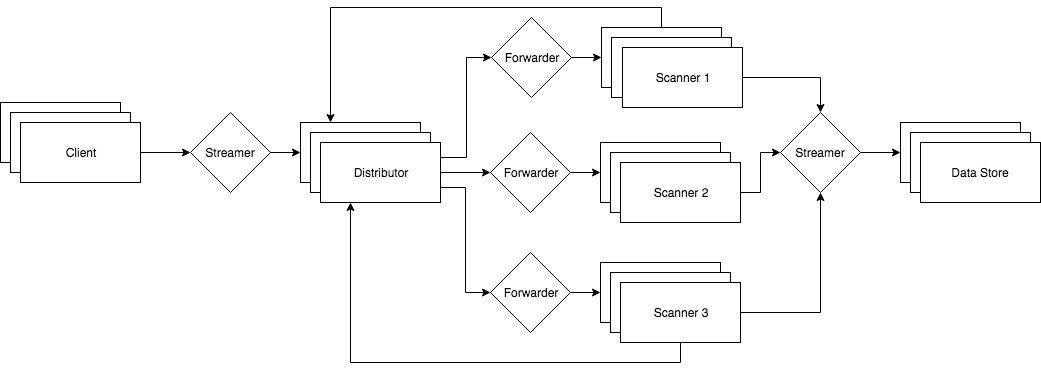
This architecture is more complex than cookie cutter: instead of two components, there are now at least six (client streamer, distributor, scanner forwarder, scanner, scanner streamer, data store). But wait, it gets worse! This example only shows three scanners – today, Strelka has almost 50 scanners!
In this model, each scanner would be a microservice and, because every scanner would require its own forwarder, we have taken a single component and now turned it into nearly 100 components. Wow, that sucks!
Advantages of Microservices
After creating the design above and realizing that microservices would be a very bad thing for this system, I wondered if I could play devil’s advocate and create a list of reasons why microservices would be better than cookie cutter scaling. There are two: multi-language support and parallel scanner processing. (To understand the importance of the second one, you should know that Strelka scans files serially.)
Both of these advantages bring the promise of theoretically faster file scanning. For example, if some of the components were written in Go, then the overall system should be faster. Additionally, if the file scanners ran in parallel, then the system would also go faster. However, these two things ignore a key component of how the system is designed – files are transferred once and loaded into memory.
The system moves as fast as it currently does (which, honestly, is pretty fast – the average scan time is commonly less than one second) because files are transferred over the network once and read into memory once. In a microservices architecture, the system will incur more latency because the same file will have to be transferred and read many more times (once per component).
In practice, this could mean that the speed gained via multi-language support and parallel scanning is offset by network latency. That’s just from a performance perspective and doesn’t take into account the increase in operational complexity that comes with building and managing microservices–none of which are worth the hassle to potentially gain a few milliseconds in scan time per file.